[OCR/AI] OCR 성능 평가: 8가지 파이썬 API 비교평가 테스트 (23년도 최신버전)
안녕하세요! 오랜만에 OCR 포스팅으로 돌아왔습니다 :) 국내외로 OCR 오픈소스 라이브러리 및 유료 서비스들이 다양하게 출시/배포되고 있는데요! 보통 저희가 어떤 서비스가 나의 목적에 가장 적절할까? 라는 질문으로 여러 서비스들을 테스트 해보고 결정하기까지 생각 보다 많은 공수가 들곤 합니다. 각각의 API 들이 어느 정도의 인식률 및 성능을 보여줄까? 속도는 어떨까? 어떤 서비스들을 후보로 검토해보면 좋을까? 등등 다양한 관점에서 살펴볼 수 있겠죠? 저도 영수증 항목을 표준화 하는 프로젝트를 짧게 진행하면서 OCR 서비스를 사용하게 되면서, 서비스들을 간략하게 비교평가한 내용이 있으면, 처음 서비스를 테스트 해야할 때의의 소요 시간, 막막함, 귀찮음 등등을 해소할 수 있겠다 라는 생각에서 시작된 테스트 로그 입니다.
*따라서 이번 포스팅에서는 OCR의 대표적인 서비스 8가지(오픈 소스, 유료 서비스 포함)를 5가지 테스트 이미지로 테스트 하면서 휴리스틱하게 비교평가한 내용을 다룹니다.
*각 서비스의 상세한 API 사용법 및 테스트 로그는 별도로 블로그에 정리해놓았습니다.
OCR(Optical Character Recognition) 이란?
![]()
“텍스트 이미지를 기계가 읽을 수 있는 포맷의 디지털 이미지 파일로 변환하는 기술” 이 사전적인 의미이나, 우리가 핸드폰 카메라로 사진을 찍었을 때, 사진 속 텍스트를 인식 해주는 "사진 속 글자 인식" 기능을 생각하면 바로 이해가 가실 겁니다!
기술 원리
"OCR = Text Detection + Text Recognition"
OCR은 Detection, Classification, Segmentation 기법이 결합된 형태로, 최근에는 속도를 개선하거나 프로세스를 조정하는 등 다양한 형태로 발전하고 있습니다. OCR 엔진에는 여러 OCR 모델과 알고리즘이 단계 별 task를 수행합니다. Text detection과 Text Recognition이 가장 중심적인 task 이며, 전체적인 워크 플로우는 아래와 같습니다.
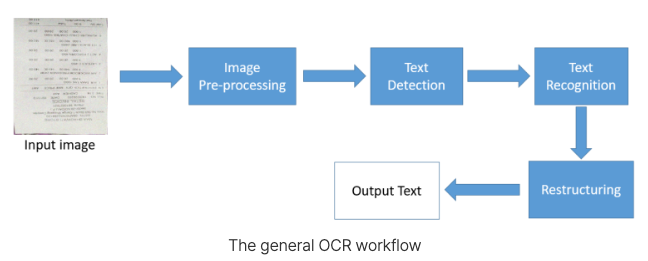
- 이미지 전처리: 스캔된 문서를 기울기 보정, 얼룩 제거 등 손상된 이미지를 복구
- Text Detection: Object Detection의 확장 버전이라고 볼 수 있고, 검출된 영역의 문자가 무엇인지 인식하는 과정
- Text Recognition: 이 과정을 통해 텍스트와 함께 이미지 내 좌표 정보 획득
- Restructuring: input image에 있던 좌표에 따라 텍스트를 재배치. 재구성된 데이터는 원본 이미지와 구조적으로 유사한 형태로 생성됨.
ex>
이름: 오수은->[오수은]은 이름이다
Why Does it Matter? OCR이 주목받는 이유
OCR은 기업의 이미지 및 문서 처리 업무를 자동화하여 프로세스 효율화 및 비용 절감에 큰 효과가 있다고 평가 받고 있습니다. 기존의 대다수 비즈니스에서는 인보이스, 계약서, 영수증, 사업자등록증 등 여러 형태의 인쇄 매체 정보를 수신하는 과정을 포함하고 있기 때문에, 단순 반복적인 RPA와 같은 업무 프로세스에서 사람의 공수를 효과적으로 절감할 수 있는 기술입니다.
테스트
8가지 서비스의 API를 5가지 테스트 이미지를 가지고 OCR API 호출에 대한 response를 받아 인식된 텍스트 결과와 소요시간을 비교평가했습니다.
OpenCV를 활용하여 원본 이미지에서 이미지가 어떻게 detect 되고 segment 되어 영역이 나뉘는지를 보고자 했습니다.
8개의 테스트 OCR API
- 모든 테스트는 Colab 환경, Python 언어로 진행되었습니다.
- Tesseract
- EasyOCR
- Google Cloud Vision
- AWS Textract
- Azure Document Intelligence (Form Recognizer)
- Naver Clova
- Upstage
- PaddleOCR
5가지 테스트 케이스
5가지의 이미지를 테스트하여, OCR 인식된 결과(텍스트 메세지)와 소요시간을 휴리스틱하게 비교평가 했습니다.
- 한글 영수증: 식음료 항목
- 영문 영수증: Whole Foods Market 식료품 마트 영수증
- 한글 문서 + 표: ChatGPT 보고서 PDF 1 페이지
- 영문 pdf 문서 + 표: HuggingFace AWS PDF 1페이지
- 영문 form: 유학생 비자에 필요한 정부 서류 (I-20 sample form)

케이스별 특징
- 전반적으로 정형화된 5번과 같은 영문 문서의 경우, 대다수 서비스에서 인식결과가 우수했음
- 글로벌 서비스는 영문 특화된 모델이 대다수였으며, 한글 문서는 Clova나 Upstage와 같은 한국 서비스가 안정된 인식 결과를 나타냄
케이스별, 사용 모델별 등 여러 조건과 상황에 따라 인식 결과가 매우 상이하기 때문에, 테스트 하고자 하는 대상이 명확한 경우 별도로 테스트를 꼭 하기를 추천!
테스트 예시
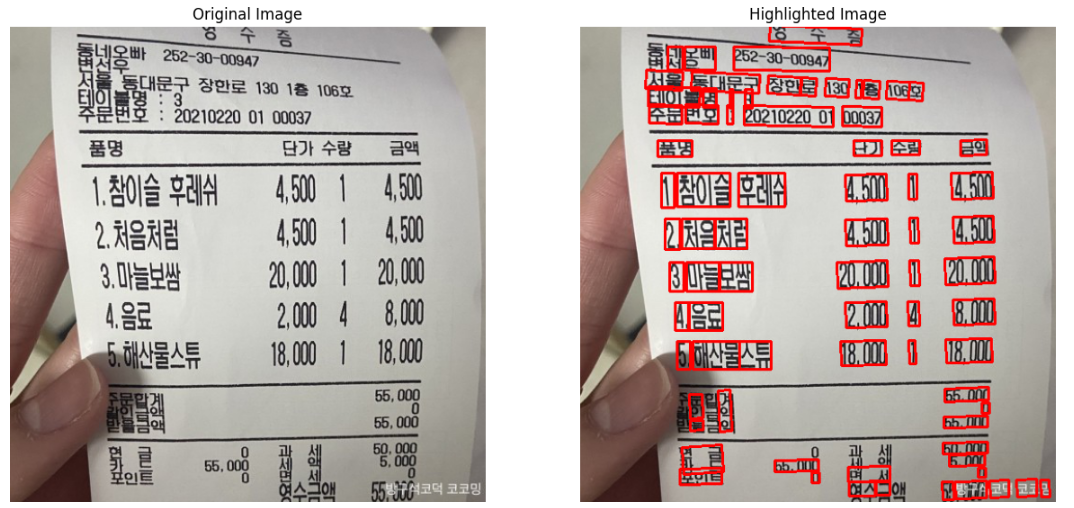
API를 활용하여 OCR 인식 결과 텍스트와 highlighed bounding box 까지 출력되도록 구현해보았습니다.
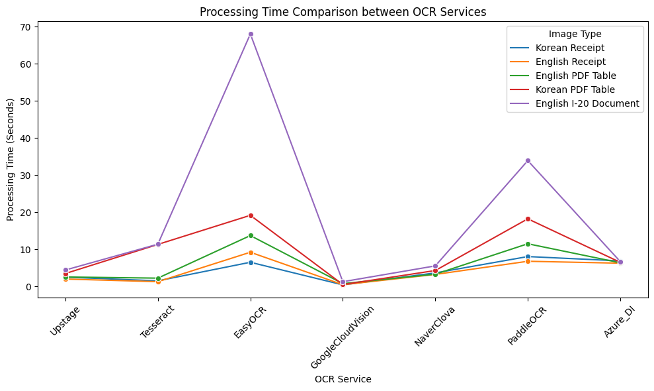
서비스별 소요 시간
서비스별, 테스트 이미지별 소요 시간을 비교한 그래프 입니다. 해당 테스트를 통해 속도 측면에서 가장 우수한 성능을 보여준 서비스는 Google Cloud Vision, Azure Document Intelligence, Upstage 와 Naver Clova 순이라고 볼 수 있을 것 같네요.
*OCR인식 결과 및 소요시간 전체 테스트 결과를 다운로드 받고 싶으시면 이 Google Drive 링크를 눌러주세요
[총정리] OCR 서비스 비교평가 테이블 (2023/11/21 기준)
| Tesseract | EasyOCR | Google Vision | AWS Textract | Azure Document Intelligence | Naver Clova | Upstage | PaddleOCR | |
|---|---|---|---|---|---|---|---|---|
| Open Source | O | O | X | X | X | X | X | O |
| 한글 인식 | 중 | 하 | 중상 | 최하(지원X) | 중상 | 상 | 상 | 중(추가 테스트 필요) |
| 영문 인식 | 상 | 하 | 상 | 상 | 상 | 상 | 상 | 상 |
| 표+글자 인식 | 하 | 하 (유료 Enterprise용 별도 존재) | 상 | 상(Only Eng) | 상 | 중상 | 상 | 중 |
| 속도 | 중 | 최하 | 최상 | 중상 | 중하 | 중 | 하 | |
| 특화 모델* 제공 | X | X | O | O | O (영수증, 명함, 보험/세금 서류, 신분증 등) | O(영수증, 명함, 사업자등록증 등) | O(영수증) | X |
| Model Customization** | O | O | X | X | O | O | X | O |
| 요금(1건)*** | 무료 | 무료 | $1.5 (매월 1000건까지 무료) | $0.01 (종량제: 매월 500페이지 무료) | 3원 (매월 300건 무료) | 3원 | 무료 | |
| API 사용 난이도 | 하 | 하 | 중상 | 중 | 하 | 하 | 하 | 중 |
| 고객 지원 | X | X | X | O | O | O | O | X |
| confidence score 제공 | O | O | △ | O | O | O | O (문서별,단어별 각각 제공) | O |
| 총평 | - 전통있는 대표적 OCR - 유료 서비스에 비해서는 전처리 해야하는 단점이 있으나 기본 사양한 충실히 해줌 |
- 쉽고 직관적인 사용법이 장점이나 한글 인식률이 매우 떨어져 활용하기 힘들어보임 - 속도 매우 느림 |
- 압도적인 속도. 초기 세팅이 상대적으로 번거로움 - 음영/그림자 등 이미지 퀄리티에 따른 인식률 차이가 있으나, 한글 및 영어 모두 괜찮은 성능을 보임 |
- 영문 데이터에 최고 - 자유도가 없으나 pre-built model 을 통해 웬만한 영문 서류 처리 가능 - 영역별 개체 인식 및 confidence score를 통해 추가 검증 가능 |
- 기존 Azure Vision 서비스 보다 고도화된 서비스 - 다양한 특화모델 제공하여 용도별 추가 테스트 필요 - 최근 출시된 V4.0부터는 네이버 Clova와 마찬가지로 “model customization”가능 - 한글 인식률 괜찮은 편 |
- 현재 가장 무난하고 우수한 한글 OCR 서비스 - 다양한 특화 모델 제공하며, 특화 모델과 맞지 않는 경우 “템플릿 생성”을 통해 반복되는 양식을 train my own data 할 수 있다는 장점 |
- Documentation은 부실하고, UI/UX 또한 user-friendly 하지 않음 - 관련 reference 없는편이나, 표+글자 인식률이 휴리스틱하게 판단할 때, 가장 뛰어나 보임 |
- 다양한 모델 제공 - EasyOCR 대비 속도&성능 측면에서 우월하나, Tesseract는 테스트 이미지에 따라 상이 - 버전 컨트롤 필요 (Python 3.10 이하만 호환 →downgrade 필요) |
| 우선 검토해볼만한 서비스 | ✔ | ✔ | ✔ | ✔ |
* 특화 모델: 영수증, 사업자등록증 등 특정 문서를 학습한 OCR 모델로 보통 해당 양식의 이미지 정보가 미리 정의된 JSON 구조에 맞추어 리턴됨
**Model Customization: Fine-Tune 이라고 보면 된다. “Train with My Own Data” 를 통해 모델을 미세조정할 수 있도록 기능 제공
***요금: 1건, 일반 OCR, Base Plan 기준이며, 건수/목적에 따라 매우 상이(많은 서비스에서 특정 건까지는 무료로 제공하기도 함)
OCR 평가 방법
이번 테스트에서는 앞서 말씀 드린 것처럼, 저의 경험을 기반으로 여러 서비스들을 비교평가했습니다. 이 외에, 정량적으로 OCR을 평가할 수 있는 방법들이 있어 간단히 소개해드리려 합니다. OCR 결과를 평가하는 데에는 여러 메트릭이 사용되는데, 원문과 인식된 텍스트 결과 간 거리 기반 유사도를 측정하여 유사도/오차를 계산할 수 있는 방법들이 있으며, 대표적으로는 (1) 정확도, (2) CER(Character Error Rate), (3) WER(Word Error Rate) 등이 있습니다. 공통점으로는, 정량적인 평가를 위해서는 원문에 대한 레이블링인 ground truth text 가 필요하다는 점입니다.
- 정확도 (Accuracy): OCR 시스템의 가장 중요한 평가 지표 중 하나입니다. 정확도는 시스템이 얼마나 정확하게 텍스트를 인식하는지를 나타내며, 일반적으로 추출된 텍스트와 실제 텍스트 간의 일치율을 통해 계산됩니다.
- 문자 오인식율 (Character Error Rate, CER): 추출된 텍스트와 실제 텍스트 간의 문자 단위 오차 비율입니다. CER은 삭제, 삽입, 대체 등으로 인한 오류를 포함합니다.
- 단어 오인식율 (Word Error Rate, WER): CER과 유사하지만, 단어 단위로 오류를 측정합니다. 이는 문맥적 정확성을 더 잘 반영할 수 있습니다.
관련된 내용은 이 포스팅에서 자세히 다루고 있으니 참고해주세요.
다음 포스팅에서는 정량적인 평가 방법을 다루는 것도 좋은 아이디어 같네요 :)
마치며
OCR을 처음 사용하거나 여러 서비스를 빠르게 테스트 해봐야 하는 분들에게 첫 단추로써 이 글이 참고가 되면 좋겠다는 마음으로 포스팅을 마칩니다.
댓글남기기